

Have you ever seen competitor content and thought, "huh, that looks familiar?" While there's nothing wrong with drawing on others for inspiration, it becomes a problem when proprietary product and pricing information, gated content, or sensitive data is involved. And that's exactly what happens in web scraping attacks.
Web scraping is a classic business logic abuse threat, commonly used by companies to keep pace with the competition. Scraping bots collect huge amounts of information, such as pricing, product descriptions, restricted data, and personally identifiable information (PII). This information can be sold on the dark web, reposted by competitors, or otherwise used to compete unfairly with your business.
Quantifying the Business Impact of Scraping
According to Aberdeen Research, “The median annual business impact of website scraping is as much as 80% of overall e-commerce website profitability.” The firm estimates that the business impact of scraping on the media sector is between 3.0% and 14.8% of annual website revenue, with a median of 7.9%.
Web scraping can have a material impact on your business, hurting your revenue and operational efficiency. It can lead to:
- Wasted infrastructure costs for bad bot traffic
- Slowed response time due to taxed bandwidth
- Theft of intellectual property, confidential content, or trade secrets
- Loss of competitive edge when pricing and product data is stolen
- Damaged search engine ranking if competitors repost your content
The Scraping Marketplace
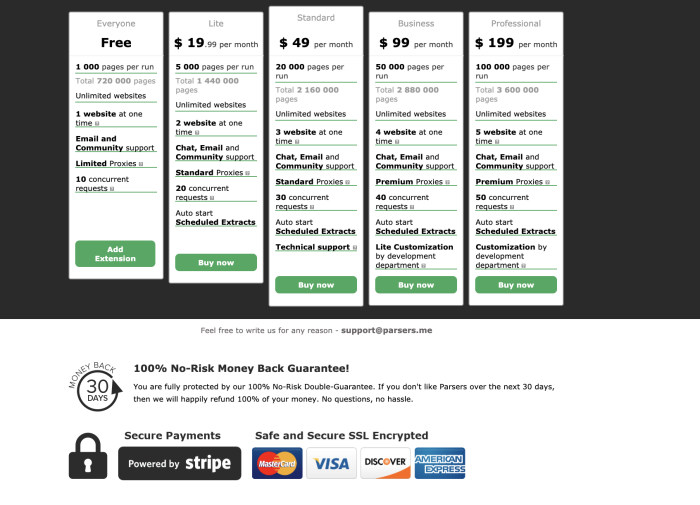
There are many publicly available, affordable services that offer web scraping services. Many have tiered subscriptions or different offerings for different types of scraping, similar to other SaaS businesses.
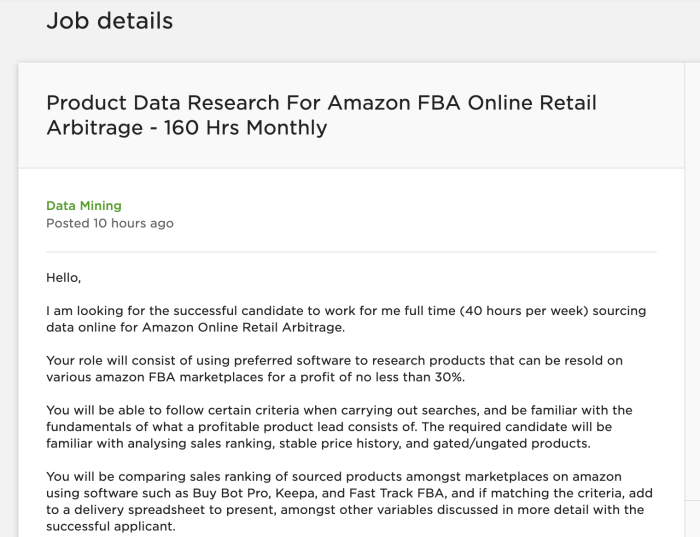
Furthermore, there are also full-time and freelance job postings from e-commerce companies looking for web developers with scraping experience. The listing shown below directly states that they want to find products that can be resold on various Amazon marketplaces for a profit of no less than 30%.
Some listings also mention that the target website is protected by a commercial bot mitigation service, a clear indication of the importance of web scraping for such companies. Developers offering scraping services make use of CAPTCHA-solving services through APIs and can automate fake account creations to get past the basic bot mitigation techniques on most websites.
How to Stop Web Scraping
Search engines and comparison sites rely on good bots to capture and aggregate product and pricing data from across the web. This makes it easy for humans to find information, so blocking all scraping bots is not an adequate solution.
Instead, businesses must be able to separate good bots from bad bots — so they can block the bad while letting the good proceed unimpeded. But as bots have become more sophisticated and programmed to mimic human behavior, identifying them is increasingly difficult.
HUMAN Bot Defender detects and mitigates scraping attacks with unparalleled accuracy. The solution uses a combination of machine learning, behavioral analysis, and predictive methods to block bad bots on web and mobile apps and APIs. This helps stop competitive assaults and prevent confidential data harvesting.


